Snap Sync
API reference: https://github.com/ethereum/devp2p/blob/master/caps/snap.md
Terminology:
- Peers: Other Ethereum execution clients we are connected to, and which can respond to snap requests.
- Pivot: The block we have chosen to snap-sync to. The pivot block changes continually as it becomes too old, because nodes don't serve old data (i.e. more than 128 blocks in the past). Read below for more details on this.
Concept
What
Executing all blocks to rebuild the state is slow. It is also not possible on ethrex, because we don’t support pre-merge execution. Therefore, we need to download the current state from our peers. The largest challenge in snap sync is downloading the state (the account state trie and storage state tries). Secondary concerns are downloading headers and bytecodes.
First solution: Fast-Sync
Fast-sync is the original method used in Ethereum to download a Patricia Merkle trie. The idea is to download the trie top-down, starting from the root, then recursively downloading child nodes until the entire trie is obtained.
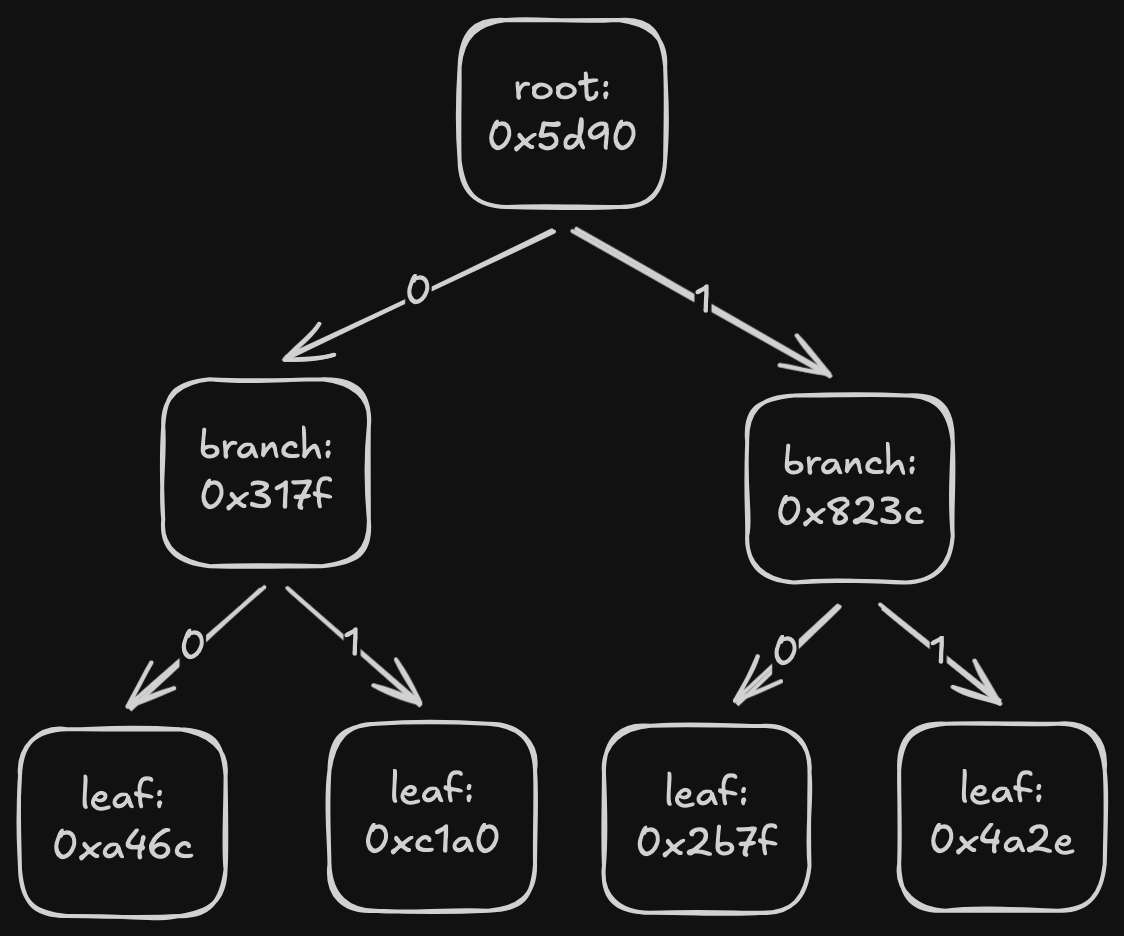

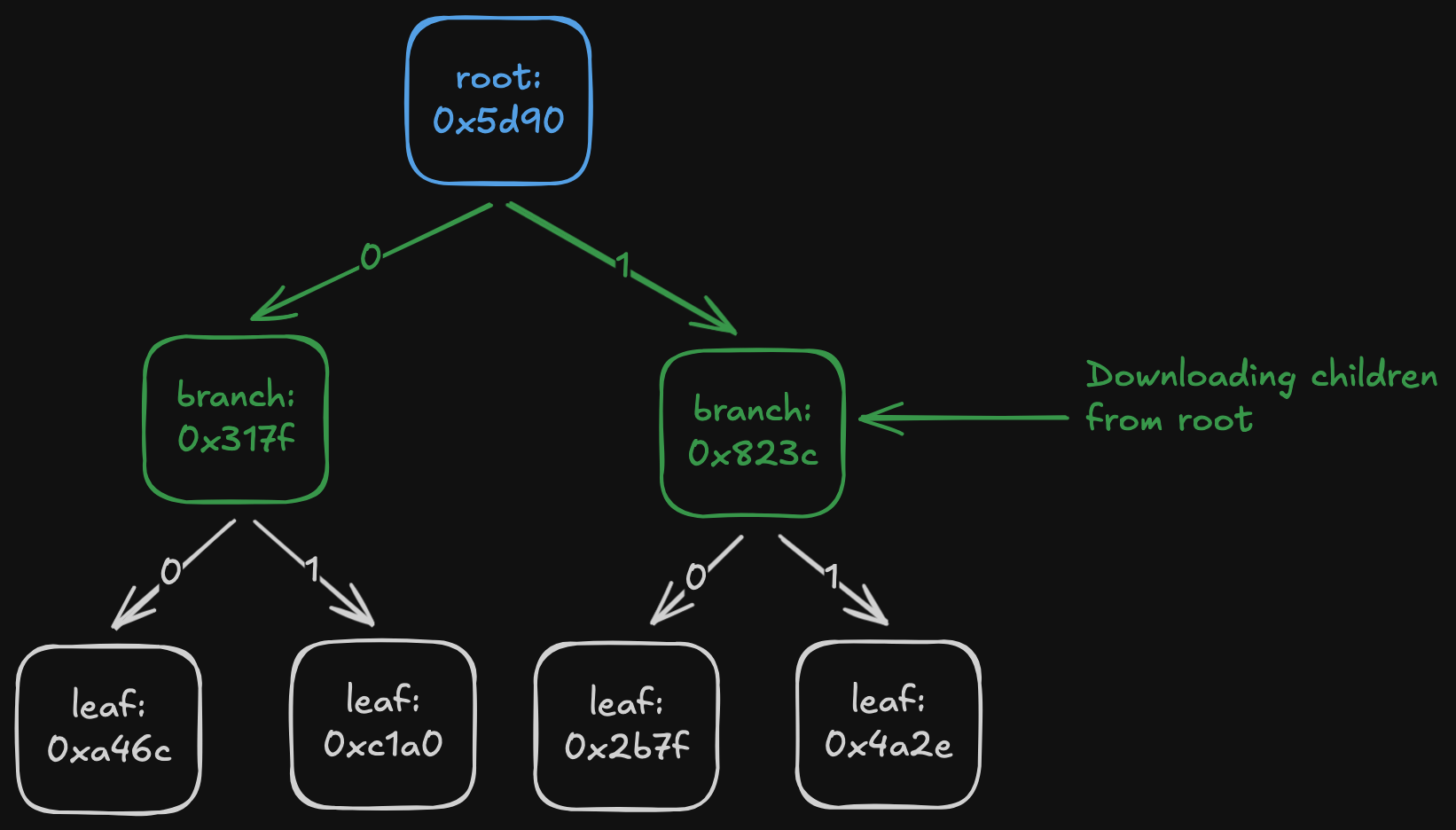
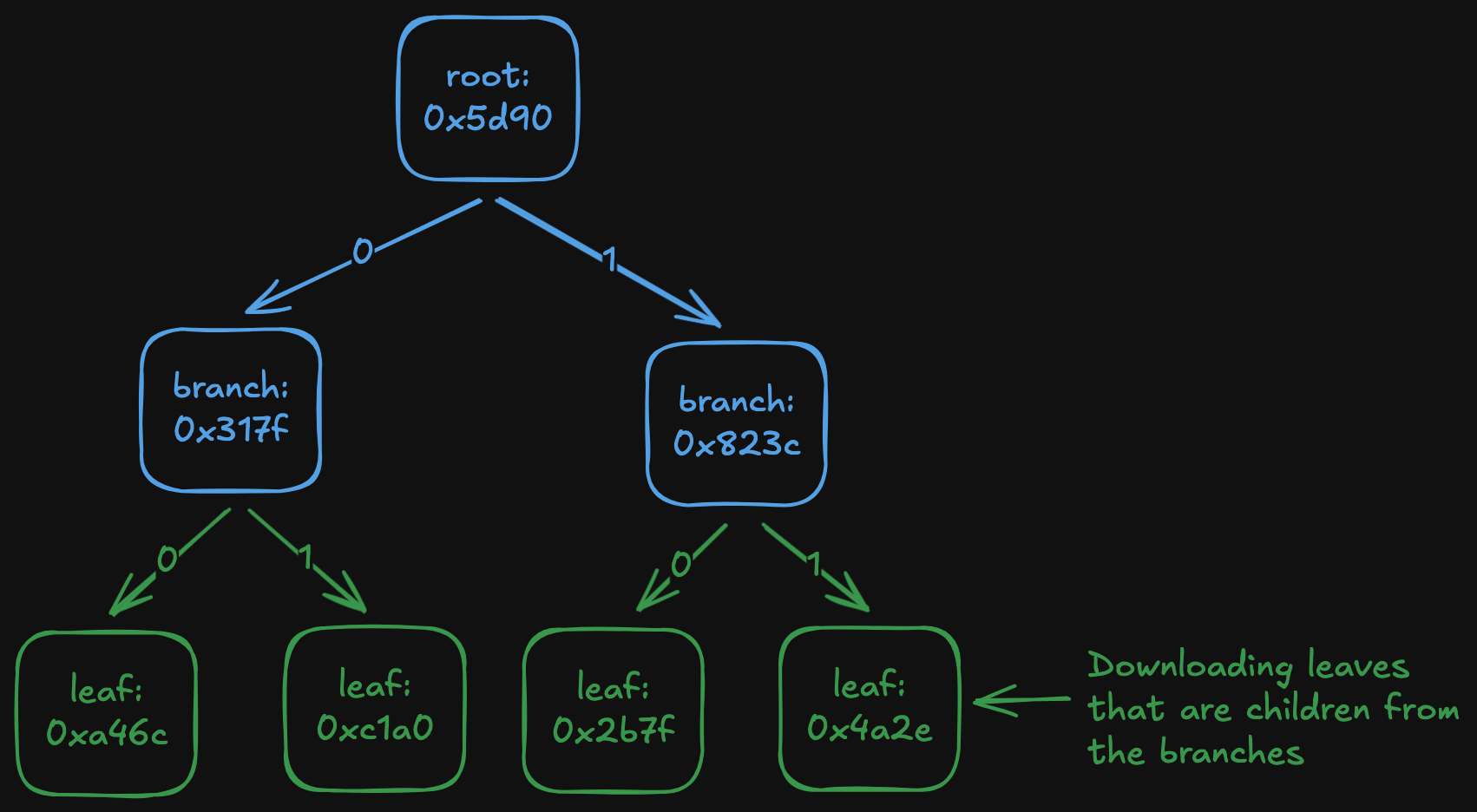
There are two problems with this:
- Peers stop responding to node requests at some point. When requesting a trie node, you specify the state root for which you want the node. If the root is 128 or more blocks old, peers will not serve the request.
- Scanning the entire trie to find missing nodes is slow.
For the first problem: once peers stop serving nodes for a given root1, we stop fast-syncing, update the pivot, and restart the process. The naïve approach would be to download the new root and recursively fetch all its children, checking each time whether they already exist in the DB.
Example of a possible state after stopping fast sync due to staleness.
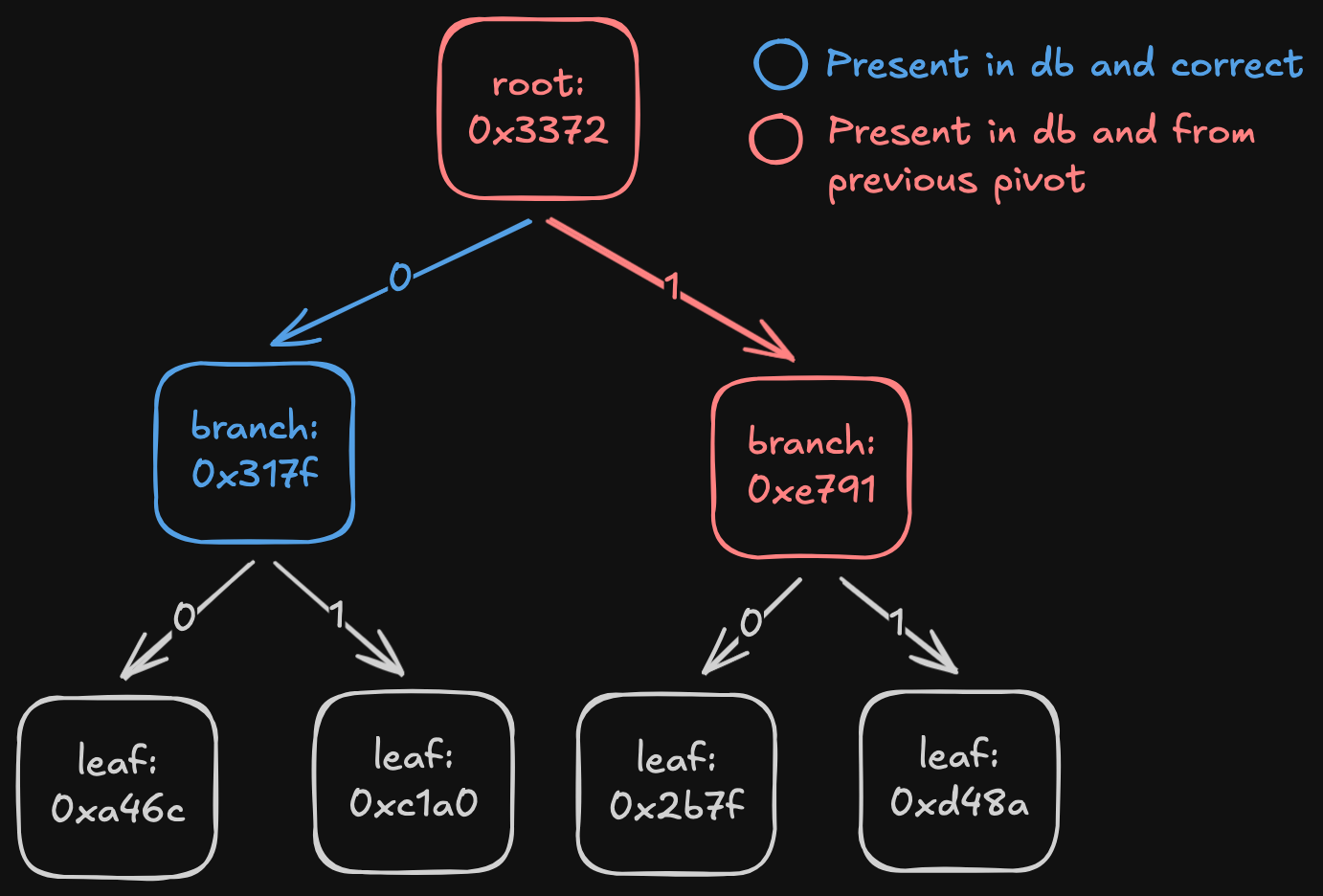
In the example, even if we find that node { hash: 0x317f, path: 0 } is correct, we still need to check all its children in the DB (in this case none are present).
To solve the second problem, we introduce an optimization, which is called the "Membatch"2. This allows us to maintain a new invariant:
If a node is present in the DB, then that node and all its children must be present.
This removes the need to explore entire subtrees: when walking down the trie, if a node is in the DB, the whole subtree can be skipped.
To maintain this invariant, we do the following:
- When we get a new node, we don't immediately store it in the database. We keep track of the amount of every node's children that are not yet in the database. As long as it's not zero, we keep it in a separate in-memory structure "Membatch" instead of on the db.
- When a node has all of its children in the db, we commit it and recursively go up the tree to see if its parent needs to be commited, etc.
- When the nodes are written to the database, all it's parents are deleted from the db, which preserves the subtree invariant. Because lower down nodes are always written first, we never delete a valid node.
Example of a possible state after stopping fast sync due to staleness with membatch.

Speeding up: Snap-Sync
Fast-sync is slow (ethrex fast-sync of a fresh “hoodi” state takes ~45 minutes—4.5× slower than snap-sync). To accelerate it, we use a key property of fast-sync:
Fast-sync can “heal” any partial trie that obeys the invariant, even if that trie is not consistent with any real on-chain state.
Snap sync exploits this by:
- downloading only the leaves (the accounts and storage slots) from any recent state
- assembling a trie from these leaves
- running fast-sync (“healing”) to repair it into a consistent trie. In our code, we call the fast-sync step "healing".
Example run:
- We download the 4 accounts in the state trie from two different blocks
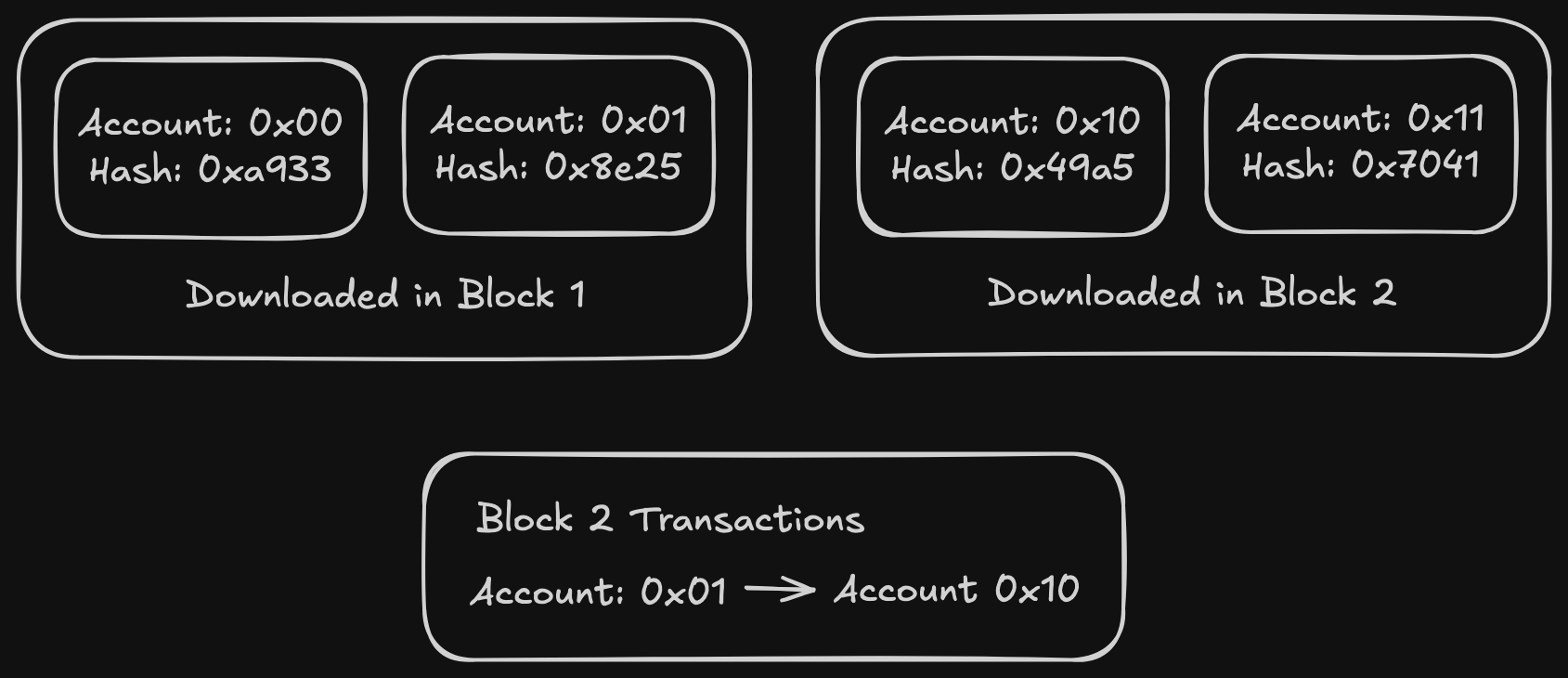
- We rebuild the trie
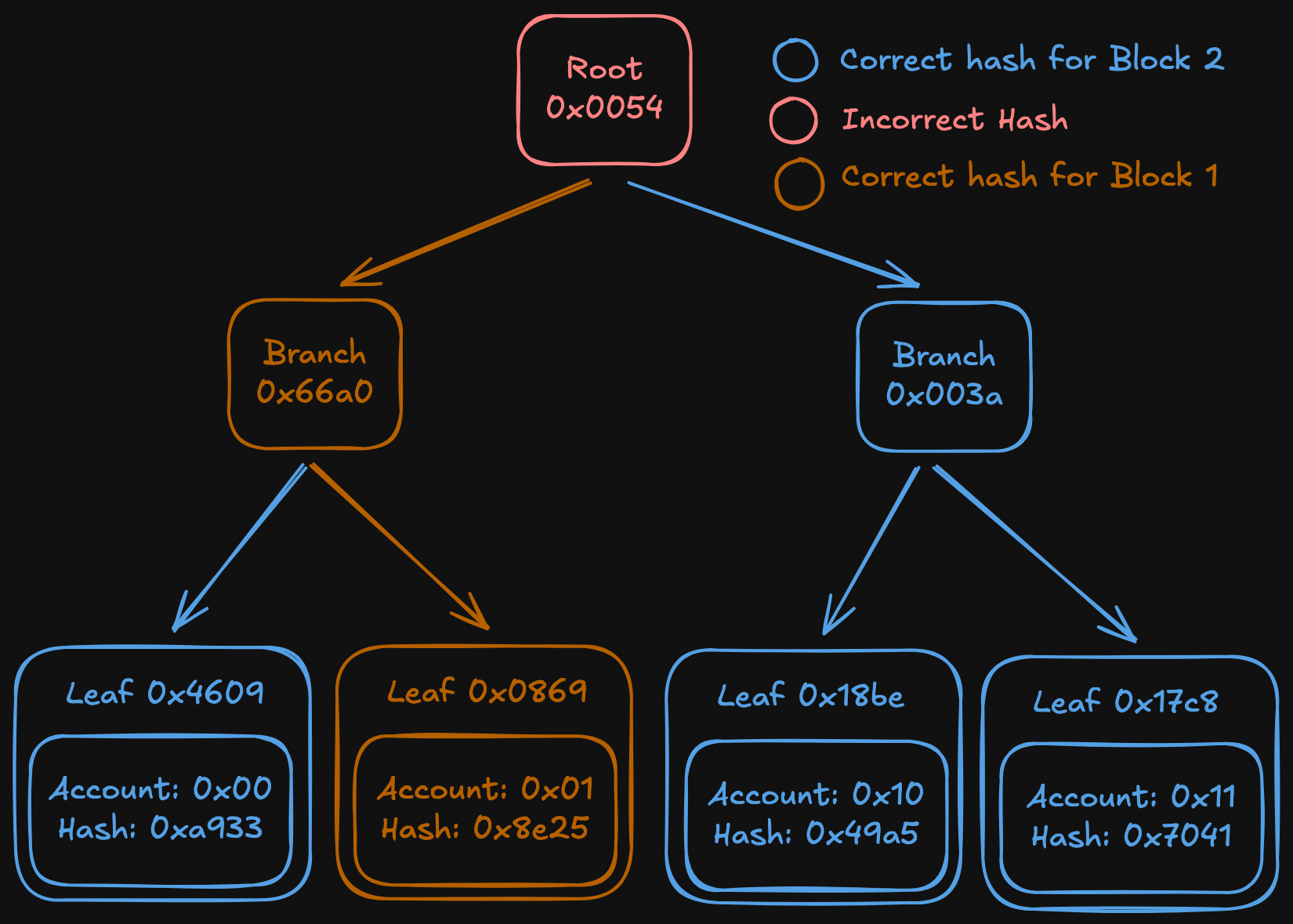
- We run the healing algorithm and get a correct tree at the end of it
This method alone provides up to a 4-5 times boost in performance, as computing the trie is way faster than downloading it.
Implementation
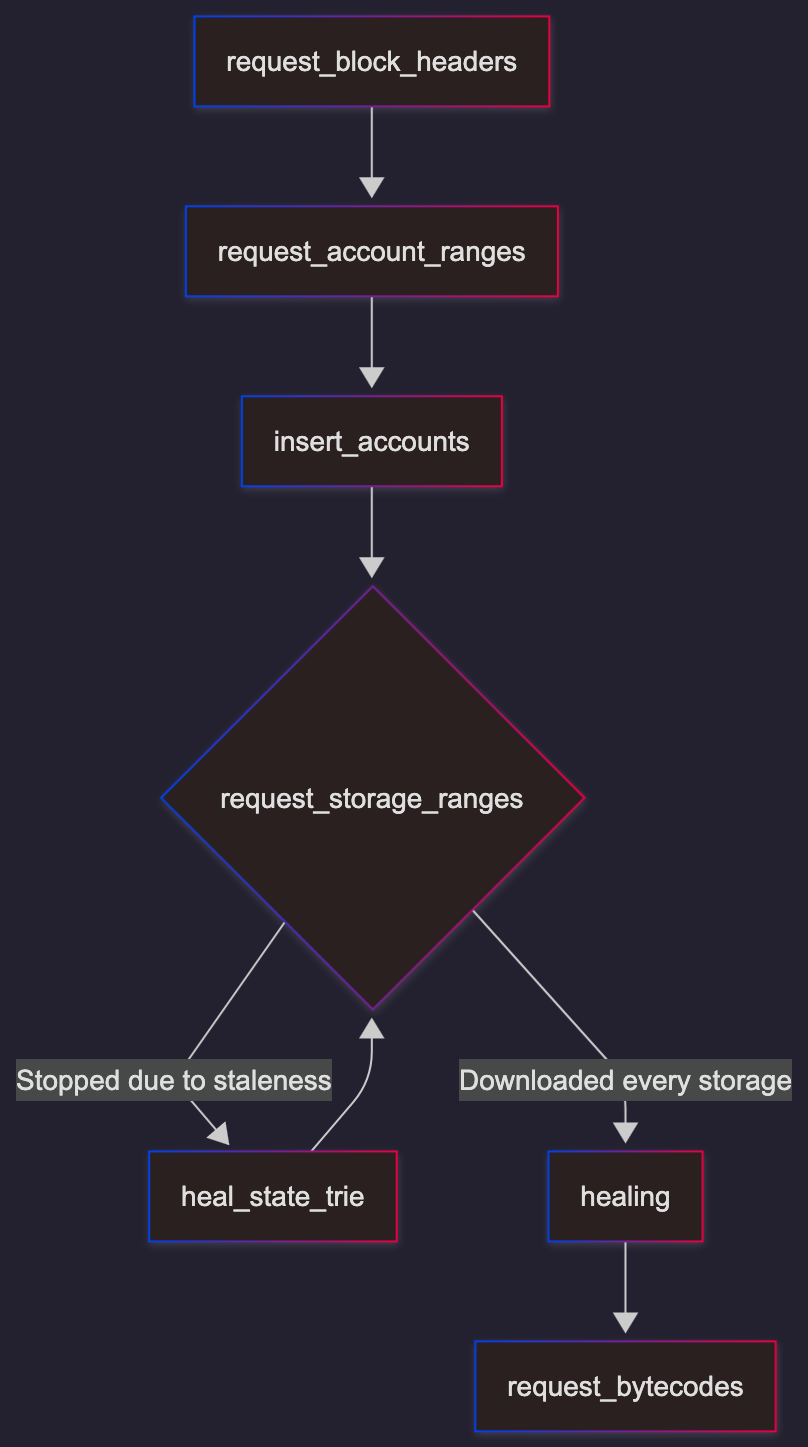
Generalized Flowchart of snapsync
Flags
When developing snap sync there are flags to take into account that are used only for testing:
-
If the
SKIP_START_SNAP_SYNCenvironment variable is set and isn't empty, it will skip the step of downloading the leaves and will immediately begin healing. This simulates the behaviour of fast-sync. -
If debug assertions are on, the program will validate that the entire state and storage tries are valid by traversing the entire trie and recomputing the roots. If any is found to be wrong, it will print an error and exit the program. This is used for debugging purposes; a validation error here means that there is 100% a bug in snap sync.
-
--syncmode [full, default:snap]which defines what kind of sync we use. Full is executing each block, and isn't possible on a fresh sync for mainnet and sepolia.
File Structure
The sync module is a component of the ethrex-p2p crate, found in crates/networking/p2p folder. The main sync functions are found in:
crates/networking/p2p/sync.rscrates/networking/p2p/peer_handler.rscrates/networking/p2p/sync/state_healing.rscrates/networking/p2p/sync/storage_healing.rscrates/networking/p2p/sync/code_collector.rs
Syncer and Sync Modes
The struct that handles the needed handles for syncing is the Syncer, and it has a variable to indicate if the snap mode is enabled. The Sync Modes are defined in sync.rs as follows.
#![allow(unused)] fn main() { /// Manager in charge the sync process #[derive(Debug)] pub struct Syncer { /// This is also held by the SyncManager allowing it to track the latest syncmode, without modifying it /// No outside process should modify this value, only being modified by the sync cycle snap_enabled: Arc<AtomicBool>, peers: PeerHandler, // Used for cancelling long-living tasks upon shutdown cancel_token: CancellationToken, blockchain: Arc<Blockchain>, /// This string indicates a folder where the snap algorithm will store temporary files that are /// used during the syncing process datadir: PathBuf, } pub enum SyncMode { #[default] Full, Snap, } }
The flow of the program in default mode is to start by doing snap sync, then we switch to fullsync at the end and continue catching up by executing blocks.
Downloading Headers
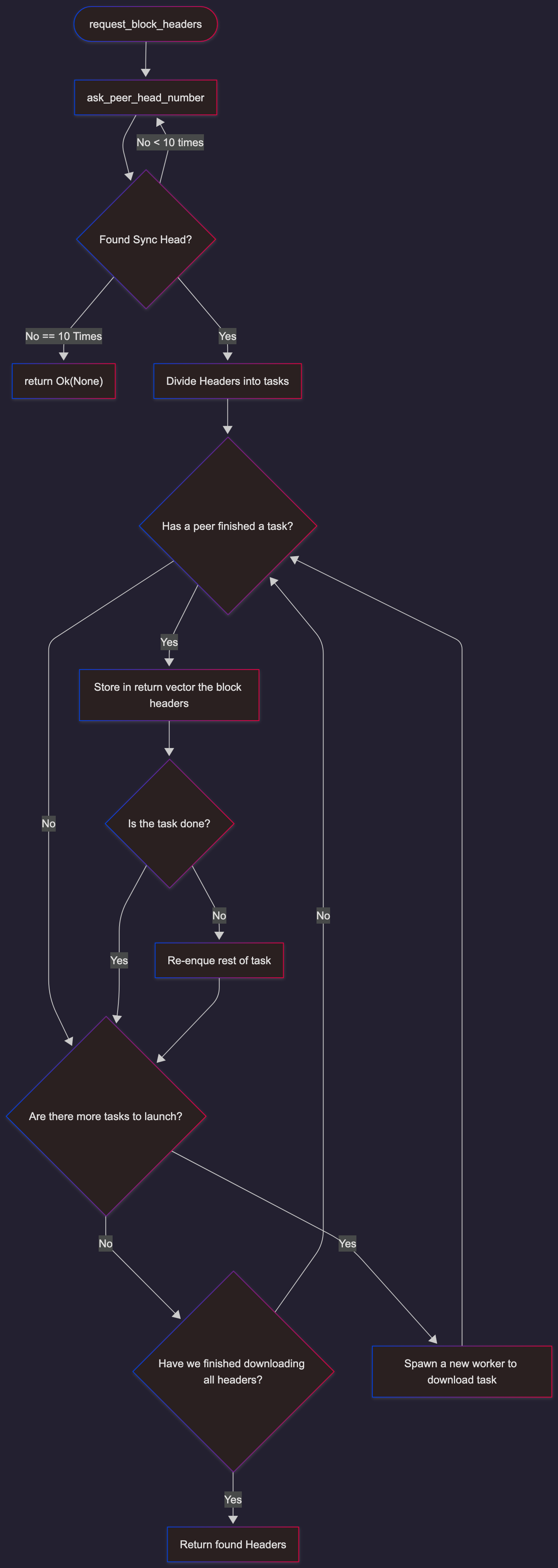
The first step is downloading all the headers, through the request_block_headers function. This function does the following steps:
- Request from peers the number of the sync_head that we received from the consensus client
- Divide the headers into discrete "chunks" to ask our peers
- Currently, the headers are divided into 800 chunks3
- Queue those chunks as tasks into a channel
- These tasks ask the peers for their data, and respond through a channel
- Read from the channel to get a task
- Finds the best free peers
- Spawn a new async job to ask the peer for the task
- If the channel for new is empty, check if everything is downloaded
- Read from the channel of responses
- Store the read result
Downloading Account Values
API
When downloading the account values, we use the snap function GetAccountRange. This requests receives:
- rootHash: state_root of the block we're trying to download
- startingHash: Account hash4 of the first to retrieve
- limitHash: Account hash after which to stop serving data
- responseBytes: Soft limit at which to stop returning data
This method returns the following
- accounts: List of consecutive accounts from the trie
- accHash: Hash of the account address (trie path)
- accBody: Account body in slim format
- proof: List of trie nodes proving the account range
The proof is a merkle proof of the accounts provided, and the root of that merkle must equal to the rootHash.
In ethrex this is checked by the verify_range function.
#![allow(unused)] fn main() { /// Verifies that the key value range belongs to the trie with the given root given the edge proofs for the range /// Also returns true if there is more state to be fetched (aka if there are more keys to the right of the given range) pub fn verify_range( root: H256, left_bound: &H256, keys: &[H256], values: &[ValueRLP], proof: &[Vec<u8>], ) -> Result<bool, TrieError> }
We know we have finished a range if the last of the accounts downloaded is to the right of the bound we have set to the request, or if the verify_range returns true.
Dump to file
To avoid having all of the accounts in memory, when their size in memory exceeds 64MiB we dump them to a new file.
These files are a subfolder of the datadir folder called "account_state_snapshots".
For an optimization for faster insertion, these are stored ordered in the RocksDB sst file format.
Flowchart

Insertion of Accounts
The sst files in the "account_state_snapshots" subfolder are ingested into a RocksDB database. This provides an ordered array that is used for insertion.
More detailed documentation found in sorted_trie_insert.md. More detailed documentation found in sorted_trie_insert.md.
Downloading Storage Slots
The download of the storage slots is conceptually similar to the download of accounts, but very different in implementation. The method uses the snap function GetStorageRanges. This requests has the following parameters:
- rootHash: state_root of the block we're trying to download
- accountHashes: List of all the account address hashes of the storage tries to serve
- startingHash: Storage slot hash of the first to retrieve
- limitHash: Storage slot hash after which to stop serving
- responseBytes: Soft limit at which to stop returning data
The parameters startingHash and limitHash are only read when accountHashes is a single account.
The return is similar to the one from GetAccountRange, but with multiple results, one for each account provided, with the following parameters:
- slots: List of list of consecutive slots from the trie (one list per account)
- slotHash: Hash of the storage slot key (trie path)
- slotData: Data content of the slot
- proof: List of trie nodes proving the slot range
From these parameters, there is a couple of difficulties that pop up.
- We need to know which accounts have storage that needs to be downloaded
- We need to know what storage root each account has to be able to verify it
To solve these issues we take two actions:
- Before we download the storage slots we ensure that the state trie is in a consistent complete state. This is accomplished by doing the insertion of accounts step first and then healing the trie. If during the storage slot download the pivot becomes stale, we heal the trie again with the new pivot, to keep the trie up to date.
- When inserting the accounts, we grab a list of all the accounts with their storage root. If the account is healed, we marked the storage root as
None, to indicate we should check in the DB what is the state of the storage root.
The time traveling problem
During snap sync development, we kept running into a problematic edge case: what we call "time traveling". This is when a certain account is in state A at a certain pivot, then changes to B in the next pivot, then goes back to A on a subsequent pivot change. This was a huge source of problems because it broke an invariant we assumed to be true, namely:
- If an account changes its state on pivot change, we will encounter it during state healing. This is NOT true if the trie is hash based.
The reason for this is the time traveling scenario. When an account goes back to a state we already have on our database, we do not heal it (because we already have it), even though its state has changed. This means the code won't realize the account has changed its storage root and won't update it.
This should not be a problem in a path based trie (which we currently have), but it's important to keep it in mind and make sure that whatever code we write keeps this time traveling edge case in mind and solves it.
Repeated Storage Roots
A large amount of the accounts with storage have exactly the same storage as other accounts.5 As such, when we are creating tasks for download, it's important to group the tasks by storage root and not download them twice.
Big Accounts
Storage trie sizes have a very uneven distribution. Around 70% of all ethereum mainnet contracts have only 1 or 2 storage slots. However, a few contracts have more storage slots than all account leaves in the entire state trie. As such, the code needs to take this pareto distribution into account to download storage tries fast.
At the beginning of the algorithm, we divide the accounts into chunks of 300 storage roots and their corresponding accounts. We start downloading the storage slots, until we find an account whose storage doesn't fit into a single requests. This will be indicated by the proof field having the data indicating that there are still more nodes to download in that account.
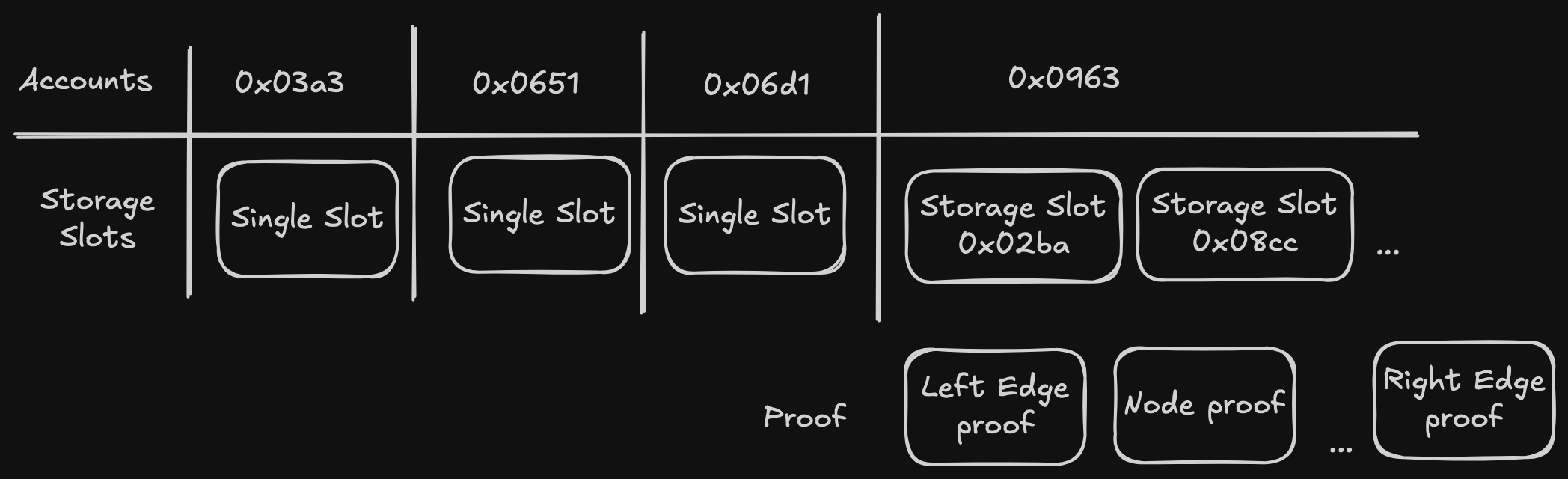
When we reach that situation, we chunk the big account based on the "density"6 of storage slots we downloaded, following this code to get chunks of 10,000 slots7. We create the tasks to download those intervals, and store all of the intervals in a struct to check when everything for that account was properly download.
#![allow(unused)] fn main() { // start_hash_u256 is the hash of the address of the last slot // slot_count is the amount of slots we have downloaded // The division gives us the density (maximum possible slots/actual slots downloaded) // we want chunks of 10.000 slots, so we multiply those two numbers let storage_density = start_hash_u256 / slot_count; let slots_per_chunk = U256::from(10000); let chunk_size = storage_density .checked_mul(slots_per_chunk) .unwrap_or(U256::MAX); }
Tasks API
#![allow(unused)] fn main() { struct StorageTask { // Index of the first storage account we want to download start_index: usize, // Index of the last storage account we want to download (not inclusive) end_index: usize, // startingHash, used when the task is downloading a single account start_hash: H256, // end_hash is Some if the task is to download a big task end_hash: Option<H256>, } struct StorageTaskResult { // Index of the first storage account we want to download start_index: usize, // Slots we have successfully downloaded with the hash of the slot + value account_storages: Vec<Vec<(H256, U256)>>, // Which peer answered the task, used for scoring peer_id: H256, // Index of the first storage account we still need to download remaining_start: usize, // Index of the last storage account we still need to download remaining_end: usize, // remaining_hash_range[0] is the hash of the last slot we downloaded (so we need to download starting from there) // remaining_hash_range[1] is the end_hash from the original StorageTask remaining_hash_range: (H256, Option<H256>), } }
Big Accounts Flow

Retry Limit
Currently, if ethrex has been downloading storages for more than 2 pivots, the node will stop trying to download storage, and fallback to heal (fast sync) all the storage accounts that were still missing downloads. This prevents snap sync from hanging due to an edge case we do not currently handle if an account time travels. See the "snap sync concerns" document for details on what this edge case is.
Downloading Bytecodes
Whenever an account is download or healed we check if the code is not empty. If it isn't, we store it for future download. This is added to a list, and when the list grows beyond a certain size it is written to disk. After the healing is done and we have a complete state and storage tree, we start with the download of bytecodes, chunking them to avoid memory overflow.
Forkchoice update
Once the entire state trie, all storage tries and contract bytecodes are downloaded, we switch the sync mode from snap to full, and we do an apply_forkchoice to mark that as the last pivot as the last block.
-
We update pivots based only on the timestamp, not on the peer response. According to the spec, stale roots return empty responses, but Byzantine peers may return empty responses at arbitrary times. Therefore, we rely on the rule that nodes must keep at least 128 blocks. Once
time > timestamp + 128 * 12we mark the pivot as stale. ↩ -
The membatch is an idea taken from geth, and the name comes from their code. The name should be updated to "pendingNodes" as it reflects it current use. ↩
-
This currently isn't a named constant, we should change that ↩
-
All accounts and storages are sent and found through the hash of their address. Example: the account with address 0xf003 would be found through the 0x26c2...38c1 hash, and would be found before the account with adress 0x0001 whose hash would be 0x49d0...49d5 ↩
-
This may be for a variety of reasons, but the most likely is ERC20 tokens that were deployed and never used. ↩
-
actually specific volume (maximum possible slots/actual slots downloaded) ↩
-
10_000 slots is a number chosen without hard data, we should review that number. ↩